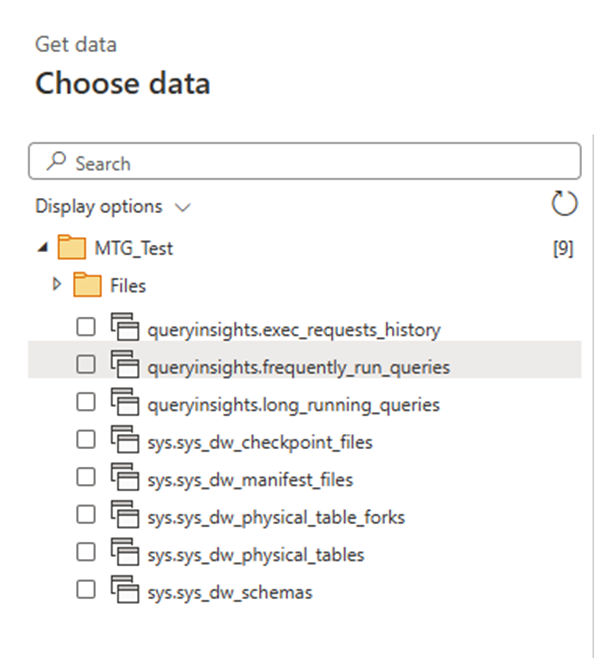
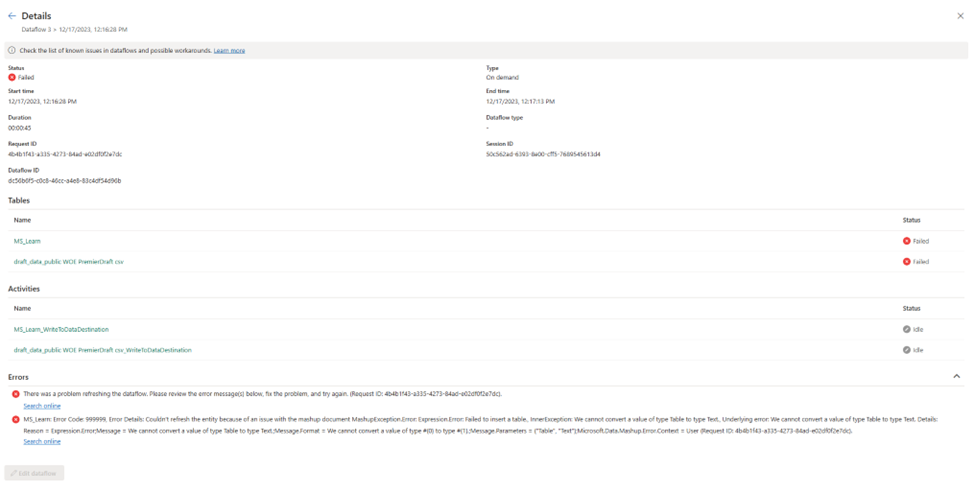
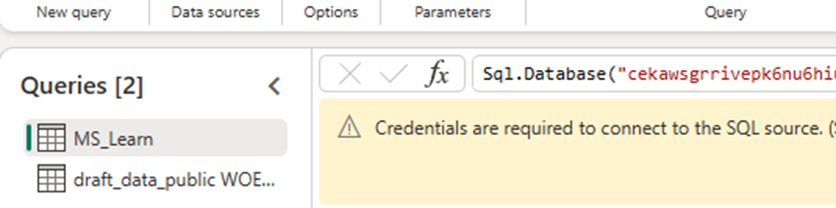
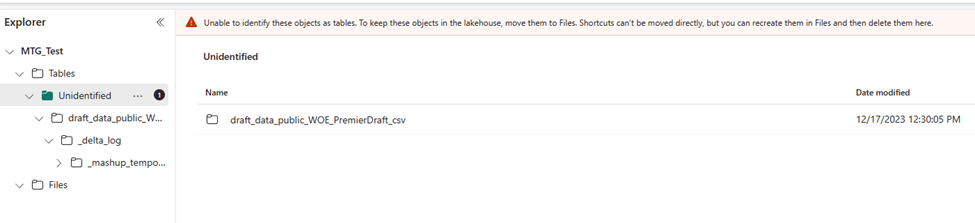
Content warning: burnout, health issues
I have not been looking forward to writing this blog post. I started the series, inspired by Brent Ozar’s series, because being able to see how the other side lived helped me to evaluate the risks and take the leap to work for myself. Unfortunately, that commitment means writing about one of the worst years of my career, and what has felt largely like a waste.
A health scare
2023 started off in a state of burnout, techniques for recovery that worked in the past had stopped working. I was forced to try taking 2 consecutive weeks off for the first time in my career, and it helped dramatically. Also, during this time I was panicking about the change in payments from Pluralsight, and I reached out to everyone I could think of who sold courses or had a big YouTube channel for advice. Thank you to everyone who spent the time to help.
As a result I had decided I was going to start selling my own, self-hosted courses. I think I had hoped that I could just ramp up the social media a smidge, ramp down the consulting a smidge, and make it all work. If I could go back in time, I would have cut down on all extraneous commitments and focused just on this. Instead, I tried to make it all work, because of what I thought I “should” be able to accomplish, or what I had been able to accomplish in years past.
Around this same time, Meagan Longoria (along with others) convinced me at SQLBits to raise my consulting rates by 30%. Meagan has the tendency to be painfully blunt, while also being kind and empathetic. I think it’s difficult to nail both candor and kindness at the same time.
The health scare came in March, when I started weighing myself again. Travel from Bits and work had caused me to fall out of habit with exercising. What I found was I was the heaviest I had been in my entire life at 300 lbs. Even heavier than when I was in college and considered myself fairly obese. I had gained 20 lbs in 3 months, which as a diabetic is very very bad.
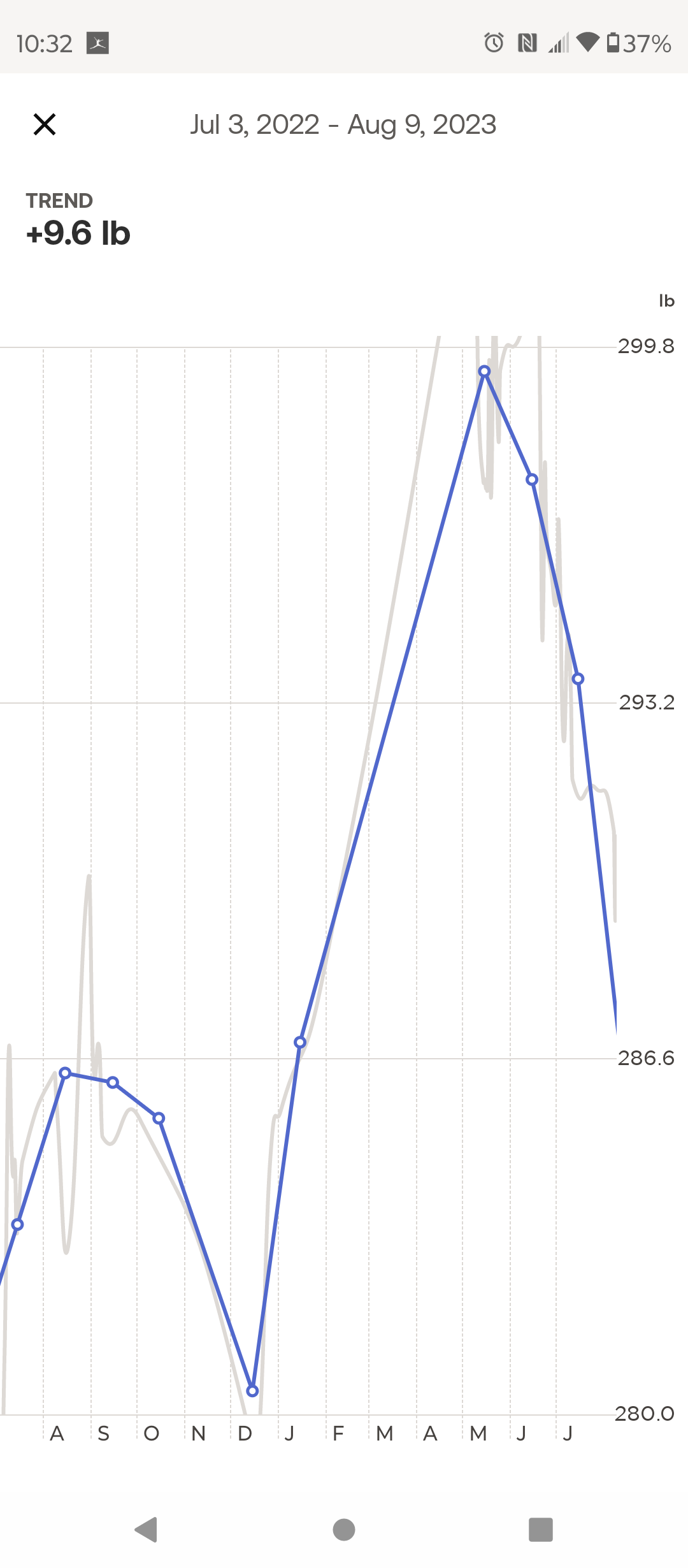
Barreling towards burnout
I decided I needed to do something, so I bribed myself with a Magic the Gathering booster every morning I exercised, and a Steam Deck if I could do that daily for 3 consecutive months. Overall, that worked, but I did find that in my mid 30s, it’s hard to just push through like that. I have to be careful, or I’ll develop plantar fasciitis or some other issues for a while.
At the same time, however, my work requirements had picked up. I had signed up for a volunteer position with a local organization that had become very stressful. I had work projects that had dragged on longer than they should and were starting to frustrate my customers. And I had found that the branding and marketing of selling my own courses involved much much more work and executive function than I had realized.
I did end up contracting and then hiring part time a local college grad to be my marketing assistant. She was recommended via a close professor friend of mine and overall she has been great. The biggest challenge has been acclimating someone to our particular niche of the data space and what the community is like.
Around June, I realized I was simply spread too thin. I had experienced being physically unable to get out of bed any sooner than was physically necessary. I was physically unable to get up an hour early for work to try to push through a project or deadline. I was should-ing myself to death, taking on more than I could handle because I thought I should be able to do more, because I thought people would be disappointed in me if I had to close out projects and work.
Ultimately, the largest threat to my health and well-being was my own personal pride.
Turning the corner
Thankfully I did decide to wind down as much of my consulting work as I could. It took multiple months longer than I would have preferred, honestly. I closed out any open projects that I could easily do so, and now I’m down to 2 customers that are a few hours per week. I also decided that I wouldn’t take on any new projects during November or December.
I’ve also been focusing on making that course and I officially have given myself a hard deadline of February 5th. At the moment I have absolutely no idea how well it will do. If it does well, that means I can continue to focus on making training content for a living. If not, I’ll have to consider pivoting into more of a focus on consulting or going back to a regular job. I would have preferred to be releasing this in the summer of 2023, but here we are.
I think the hardest thing to grapple with regarding burnout, is the uncertainty of how long it will take to recover and how aggressive you have to be in resting to recover. I’m grateful to both Matthew Roche and Cathrine Wilhelmsen for putting that into perspective.
There are days that I feel much better, I feel energetic and enthusiastic. Coming back from PASS Summit, I felt that way all week. But at the moment it’s still fragile, and I have to remind myself that a good day in a week doesn’t mean the issue has been totally solved yet.
One other thing, I always struggle with the lack of sunlight in the winter. For the first time ever, I’m being proactive about it and going somewhere warm in December instead of January or February when the issue becomes apparent. So, I’ll be spending Christmas week in San Juan, Puerto Rico where it is currently 80 degrees Fahrenheit. See y’all on the other side of 2024.