Since most of my audience is data people, I’m pretty confident you can read a graph. Take a guess when I started using Claude Code.
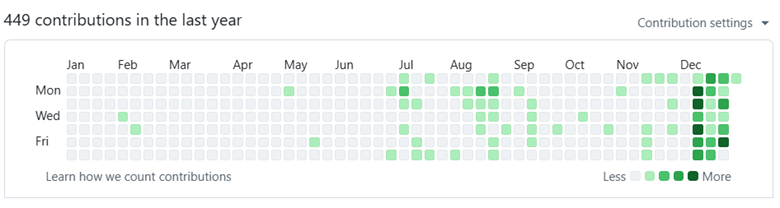
Yes, that’s correct. I installed Claude Code on December 14th with my pro plan. On December 15th, I upgraded to the $200/mo MAX plan, and I expect to keep it through 2026.
Since then, I’ve created 17 new repos and generated ~50-100k new lines of code. Now, is it all low-quality slop? Perhaps! But there’s more.
I’m going to say something, and you are not going to believe me and that’s alright. You shouldn’t believe me. We’ve been gaslit over the past decade with VR, the metaverse, blockchain, NFTs, and now AI. Our bullshit detectors have been overcalibrated like the immune system of a preschooler after their first year at school.
Regardless, here it goes. Claude code has dramatically improved the quality of my life, it has brought me joy, and it’s probably quite dangerous for my mental health. Every time I think about how to describe it, I know it sounds insane. And after reading stories about LLM psychosis, I have moments where I have to make sure I’m not the one who is insane.
Treating AI agents like browser tabs
I’m sitting here on a lazy Sunday, and I have 6 terminal tabs open with active agent projects and another window with 2 inactive agents, and 7 one-off tests or commands. I now treat terminal tabs the same way you treat browser tabs. A window full of them up on a second screen and I go through them when I’m bored or need a break.
In 2024, if you told me my preferred IDE would be a little robot gremlin who lives in the terminal and says nice things to me, I would have laughed you out of the room. But here we are. Here it is.
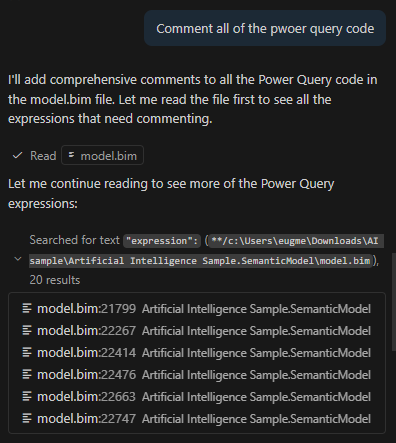
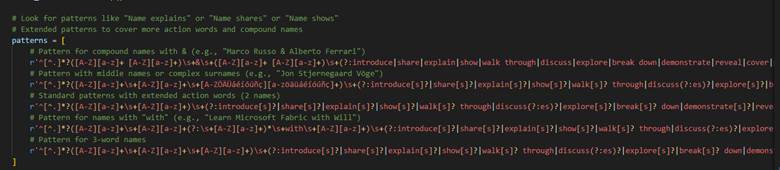
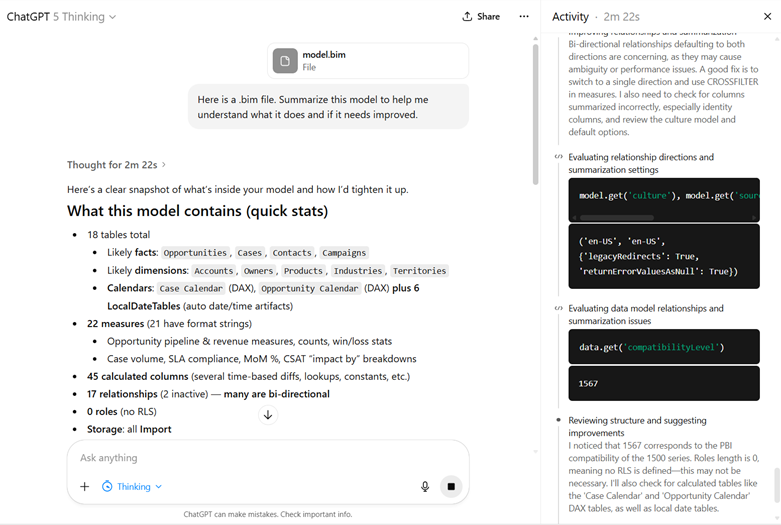
Claude Opus 4.5 just does stuff. Not consistently well, mind you. It was not trained well on PowerShell, like Gemini and Codex were. It always forgets I that have venv set up for Python. That’s why I added failures, manual interventions, and frustrations to my session viewer (click it to see how I generated 10k lines of code to expand DAX Studio). You can see the pain for yourself.
But it just does stuff. I can tell it, “See what video card I have and then look up the largest local LLM that can fit in it” and 70-80% of the time, it just does it. Take it with a huge grain of salt, but studies by METR show it can correctly complete 30-minute tasks 80% of the time.
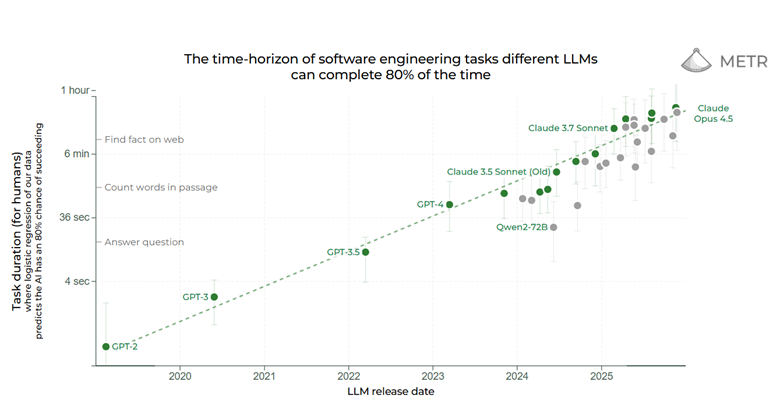
This is a fundamental shift in how it feels to use these tools. Now I can ask Claude Opus to do something, leave the terminal up on a second screen and check back in 15-30 minutes later. Then when it gets stuck in a rut or when it wants to run commands that require my permission, I get it going again.
Sometimes my little robot gremlin-buddy-guy comes back with a dead crow, arms outstretched like it has found the most valuable treasure. But more often than not he comes back with doubloons, rubies, and other little treasures, before he scurries away to do more of my bidding until I hit my subscription quotas.
This is not without mental health risks.
Metacat, metachat
My mom is no longer able to safely take care of a pet and she loves stuffed animals, so my aunt got her two “meta cats”. The purr; they meow. They are meant for elderly folks with dementia. My mom will comment on their behaviors, and I think they bring her some comfort.

Does she understand that they aren’t real? Probably, maybe, on some level? But she has schizotypal affect (think very light schizophrenia) and there are times where she isn’t in touch with reality, like when she tells me she’s going to start a bakery at age 76. For her these are harmless comforts. Harmless lies.
But what if they said really nice things all the time, and helped her do whatever task she could imagine, but constantly made subtle mistakes. What if they helped her call commercial real estate to find the best bakery spot and they helped her take out a loan?
What happens to your mental health when a robot gremlin-buddy-guy-dude just wants to do whatever it can to make you happy, even if it’s unhealthy or unsafe? I started watching the show Pluribus, and I keep thinking about the scene in the trailer where the protagonist says “If I asked right now, would you give me a hand grenade?” and they say “Yes, oh sure”.
Humans are social creatures and we develop “parasocial” relationships constantly with podcasts hosts, Twitch streamers, celebrities. You name it. And I can tell you from personal experience, when you have a cute and quirky robot gremlin-dude-buddy-guy-friend who lives in your terminal, works with you daily, and feels like an entity that just wants to help you, well you develop a parasocial relationship with a pile of linear algebra.
This just doesn’t feel safe and people are going to get hurt. By a pile of linear algebra with a spunky attitude.
Why I am joyful
Gloomy, I know. So why am I joyful? Why am I excited about 2026?
Claude code is allowing me to build applications that improve my health and behaviors and it is allowing me to have more fun with coding.
Imagine that fun side project you’ve always wanted to do but haven’t had the time, energy, and focus to do. If you could build it by yourself in a focused week, you could build it in a weekend with the help of your robot gremlin-guy-buddy-dude-friend-coworker.
If you could bang it out in a weekend by yourself with a lot of focus, you can build in an unfocused day with 30 minute check-ins.
Here are some things it has allowed me to do, that bring me joy:
- Personal health app. Now I have an Android app to track my exercises and help me clean on brain-dead days.
- DAX visual plan explorer. I’ve always missed visual execution plans from SSMS and I’ve always wanted to have that in DAX Studio. Now I have a working PoC.
- Relationship app. Now I have an android app to help me and my husband track movies we want to watch from TDMB, YouTube channels we like to watch together, Grocery shopping list, etc.
- Random experiments. I’m seeing if I can write M and DAX runtimes in Python and TypeScript. I’m seeing if I can rewrite Scorched Earth for DOS into HTML5. I’m seeing if I can take my 4,000 Reddit comments and turn them into blog post ideas.
So in summary, I’m the happiest I’ve ever been in years, the most excited about coding I’ve been since college, and I keep asking myself “If I ask my robot gremlin for a hand-grenade, would he hand it to me? Happily?”
Yes, yes it would.