This course is launching April 8th, 2025 for $10 for 24 hours. Then it will be $50 until April 13th.
Below is a summary of the contents of the course.
Module 1 – Choosing to consult
This module is a reality check on why you want to consult and what things you should consider before making the jump. Module 1 videos are available for free on YouTube and on the course site.
In addition to the videos, there are 3 bonus docs:
- Readiness Checklist. This is a checklist of thought exercises to make sure you are ready to take the leap.
- Burn Rate Calculator. This is a simple excel file to estimate your monthly income and see how many months you can work with your existing savings.
- Recommended Reading List. A list of recommended and optional reading, podcasts, and videos for each module.
Module 2 – Paperwork
Module 2 focuses on the paperwork involved with getting started. In short, you will want:
- A legal entity (preferably one that provides liability protection)
- Business Insurance (general liability and Errors & Omissions)
- In the US, you’ll want to research an S-corp tax election
- A business bank account
- A default service agreement contract
- The ability to write up a scope of work
- The ability to track your time and to send invoices
The module also includes some quick demos on tracking time with Toggl and creating an invoice.
Module 3 – Sales and Marketing
This module covers the fundamentals of sales and marketing with core concepts like the AIDA model and the sales funnel. It talks about how consulting is a high-trust work, and your sales and marketing strategy should reflect that.
Module 4 – How to Scope
The scoping section covers what goes into a scope of work, and how to estimate time and overall scope. It explains what deliverables are and how they can vary in concreteness.
It also includes a private custom GPT that you can interact with to practice gathering requirements. If you are stuck, there is a document with a list of questions to ask the GPT. I also very quickly demo using Microsoft Word to write a scope of work.
Module 5 – How to Price and Contract
This module talks about three of the main pricing models: hourly, flat rate, and value pricing. It explains how to estimate your hourly rate based on your salary and desired role.
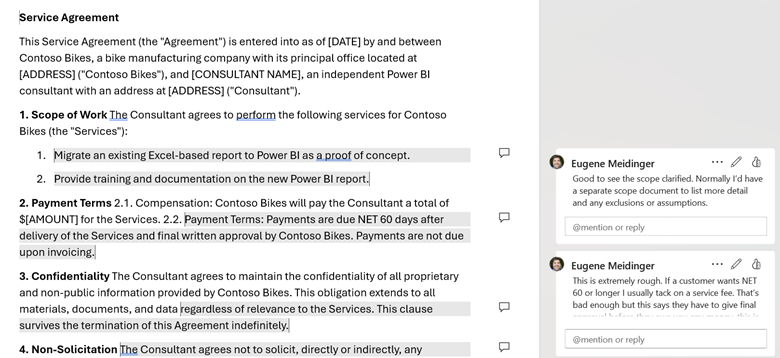
For contracting, the module covers the gist of what should go into a service agreement and what to watch out for. As an exercise, I’ve included an intentionally malicious service agreement that you need to review for problems. This exercise also has a custom GPT for practicing contract negotiation. As part of the exercise, I have a marked-up version of the contract if you are stuck finding problematic clauses.
Module 6 – Your First Project
This final module helps to answer the question of how you know you are ready skill-wise. It talks about some of the mental health hurdles to expect when working for yourself. Finally, it covers some specific technical details of Power BI consulting and that first customer.